The Humanoid Lab is a part of the CNRS-AIST JRL, located at AIST, Tsukuba about 5km from the main campus of the University of Tsukuba.
It is associated to the university through the Cooperative Graduate School System, which means that graduate students at the university
can work at JRL as Trainees and RAs under the supervision of Prof. Kanehiro (Faculty of Cooperative Graduate School, IMIS).
The lab provides a unique opportunity for graduate students to work with Japanese and foreign research scientists on a
wide variety of robot platforms and research topics. Our main research subjects include: task and motion planning and control, multimodal interaction
with human and surrounding environment through perception, and cognitive robotics.
KANEHIRO Fumio 金広 文男
f-kanehiro_*_aist.go.jp
Professor
Most members of our lab are bilingual (some are quadrilingual!),
hence, we encourage Japanese-speaking as well as English-speaking students to join our lab.
The lab is always looking for talented and motivated graduate students to join our group. Students must be accepted to the Master's or
Doctoral Program in Intelligent and Mechanical Interaction Systems (IMIS),
University of Tsukuba through the regular admission procedure (examinations held in summer and winter).
If you're interested, please contact the lab or Prof. Kanehiro directly before you start the application procedure.
(This page is maintained by current students.)
Research content
Vision-based Belt Manipulation by Humanoid Robot
Deformable objects are very
common around us in our daily life. Because
they have infinitely many degrees of freedom,
they present a challenging problem in
robotics. Inspired by practical industrial
applications, we present our research on using
a humanoid robot to take a long, thin and
flexible belt out of a bobbin and pick up the
bending part of the belt from the ground. By
proposing a novel non-prehensile manipulation
strategy “scraping” which utilizes the
friction between the gripper and the surface
of the belt, efficient manipulation can be
achieved. In addition, a 3D shape detection
algorithm for deformable objects is used
during manipulation process. By integrating
the novel “scraping” motion and the shape
detection algorithm into our multi-objective
QP-based controller, we show experimentally
humanoid robots can complete this complex
task.
sim2real: Learning Humanoids Locomotion using RL
Recent advances in deep reinforcement learning (RL) based techniques combined with training in
simulation have offered a new approach to developing control policies for legged robots.
However, the application of such approaches to real hardware has largely been limited to quadrupedal robots
with direct-drive actuators and light-weight bipedal robots with low gear-ratio transmission systems.
Application to life-sized humanoid robots has been elusive due to the large sim2real gap arising from
their large size, heavier limbs, and a high gear-ratio transmission systems.
In this work, we investigate methods for effectively overcoming the sim2real gap
issue for large-humanoid robots for the goal of deploying RL policies trained in simulation
to the real hardware.
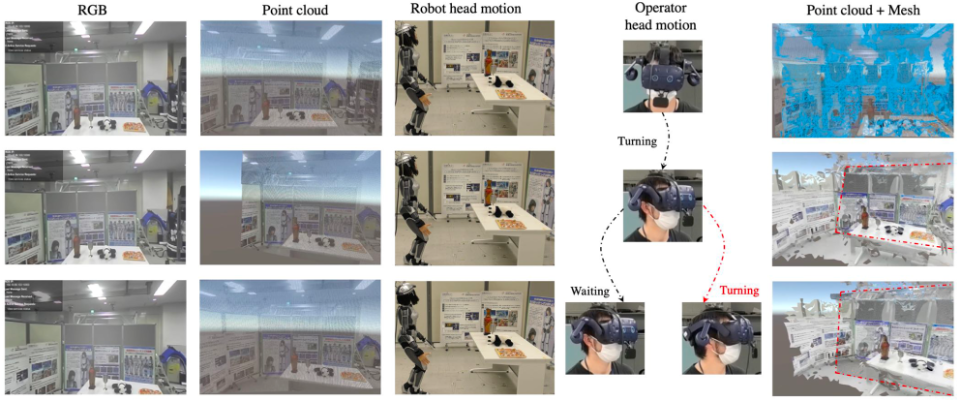
Enhanced Visual Feedback with Decoupled Viewpoint Control in Immersive Teleoperation using SLAM
During humanoid robot teleoperation, there is a noticeable delay between the motion of the
operator’s and robot’s head. This latency could cause the lag in visual feedback, which decreases the
immersion of the system, may cause some dizziness and reduce the efficiency of interaction in teleoperation
since operator needs to wait for the real-time visual feedback. To solve this problem, we
developed a decoupled viewpoint control solution which allows the operator to
obtain the visual feedback changes with low-latency in VR and to increase the reachable
visibility range. Besides, we propose a complementary SLAM solution which uses the reconstructed mesh to
complement the blank area that is not covered by the real-time robot’s point cloud visual feedback. The
operator could sense the robot head’s real-time orientation by observing the pose of the point cloud.
Bipedal Walking With Footstep Plans via Reinforcement Learning
To enable application of RL policy controller humanoid robots
in real-world settings, it is crucial to build a system that can
achieve robust walking in any direction, on 2D and 3D terrains,
and be controllable by a user-command. In this paper, we
tackle this problem by learning a policy to follow a given
step sequence. The policy is trained with the help of a set
of procedurally generated step sequences (also called footstep
plans). We show that simply feeding the upcoming 2 steps to the
policy is sufficient to achieve omindirectional walking, turning
in place, standing, and climbing stairs. Our method employs
curriculum learning on the objective function and on sample
complexity, and circumvents the need for reference motions
or pre-trained weights. We demonstrate the application of our
proposed method to learn RL policies for 3 notably distinct
robot platforms - HRP5P, JVRC-1, and Cassie, in the MuJoCo
Simultaneous localization and mapping(SLAM) in dynamic environment
Nowadays, SLAM in the dynamic environment has become a popular topic.
This problem is called dynamic SLAM where many solutions have been proposed to segment
out the dynamic objects that bring errors to camera tracking and subsequent 3D reconstruction.
However, state-of-the-art dynamic SLAM methods face the problems of accuracy and speed, which
is due to the fact that one segmentation algorithm cannot guarantee both points at the same time.
We propose a multi-purpose dynamic SLAM framework to provide a variety of selections for segmentation,
each has its applicable scene. Besides, if the user selects the semantic segmentation, the object-oriented
semantic mapping is beneficial for high level robotic tasks.
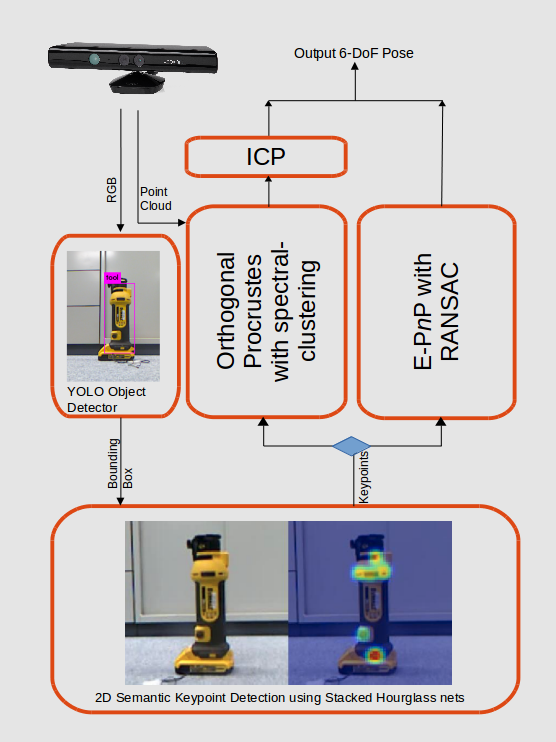
6-DoF Object Pose Estimation
For a humanoid robot to interact with objects in its surrounding environment,
it is essential for the robot to find the position and orientation of the object relative to
itself - often through the use of its vision sensors. The 3D position and roll, pitch, yaw
rotation together comprise the 6 degrees-of-freedom pose of the object. For precise grasping
and manipulation of tools, this pose needs to be estimated with a high degree of accuracy.
Further, we desire robustness against challenging lighting conditions, occlusions, and non-availability
of dense and accurate object models. This work mainly involves the use of Deep Learning based strategies
for solving problems in this sphere.
Publications
Title
Authors
Conference/Book
Year
bib
pdf
Learning to Classify Surface Roughness Using Tactile Force Sensors